

Co to jest?
Large Language Models (duże modele językowe) to termin, który zyskał na popularności wraz z rozwojem opartego na sztucznej inteligencji ChatGPT firmy OpenAI. Termin ten odnosi się do specjalnie dostosowanych modeli języka o dużym rozmiarze, takich jak GPT-3 (Generative Pre-trained Transformer 3). Są to modele uczenia maszynowego, które potrafią wykonywać zadania, wykorzystując przetwarzanie języka naturalnego (natural language processing). Modele trenowane są na bardzo dużych zbiorach danych tekstowych, aby uzyskać zdolność do generowania tekstów i rozumienia kontekstu językowego.

Do rozwoju uczenia się modeli językowych przyczynia się tzw. architektura transformatorowa. Architektura transformatora (ang. transformer architecture) opiera się na koncepcji uwagi, która umożliwia modelowi ważenie znaczenie różnych słów w danym kontekście. Jest to osiągane poprzez szereg warstw uwagi, które są ze sobą powiązane i które pomagają modelowi uchwycić zależności dalekiego zasięgu w tekście wejściowym.
LLM jest zbudowany na zasadzie enkoder–dekoder, stosowanej w wielu modelach neural machine translation (neuronowe tłumaczenie maszynowe, automatyczne tłumaczenie tekstu).
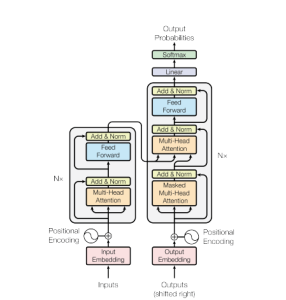
Źródło: Attention is all you need
Pojęcie architektury transformatorowej pojawiło się po raz pierwszy w 2017 roku w artykule Attention Is All You Need.
Ogromne zbiory danych
Modele językowe są trenowane na ogromnych zestawach danych, a następnie używają różnych technik do rozumienia zależności między słowami. Na podstawie tych zależności są w stanie generować nowe treści. Takie modele wykorzystuje się w aplikacjach przetwarzania języka naturalnego (NLP), gdzie użytkownicy wprowadzają zapytania w języku naturalnym. Im więcej danych dostarczymy do trenowania modeli, tym większe będą ich możliwości.
Nie istnieje liczba określająca, jakie jest minimum danych potrzebnych do szkolenia, LLM zawiera jednak zazwyczaj co najmniej miliard parametrów. Parametry to wszystkie zmienne, które są używane przez model i na podstawie których dany model wnioskuje i generuje informacje.
Jak to działa?
Stworzenie dużego modelu językowego jest trudne i skomplikowane, a także kosztowne, dlatego też niewiele firm może sobie na to pozwolić. Często taka opcja pozostaje poza zasięgiem wielu przedsiębiorstw. Zapewnienie dużej skuteczności LLM wymaga przeszkolenia modelu na dużych objętościowo i odpowiednio przygotowanych zbiorach danych. Model uczy się na dostarczonych mu danych, np. wykorzystuje zbiór danych dostępnych w internecie.

Dane wejściowe są wprowadzane do modelu, a następnie zostają poddane procesowi tzw. uczenia nienadzorowanego (unsupervised learning), co oznacza, że ingerencja człowieka w proces nauki jest minimalna. Model nie otrzymuje zatem żadnych instrukcji dotyczących traktowania i wykorzystywania danych, co sprawia, że wnikliwie analizuje dane wejściowe, zależności i relacje, jakie występują między danymi. Po zakończeniu takiego procesu model może odgadywać np. zakończenia fraz, zdań lub tworzyć całe teksty na zadany temat, może sformułować odpowiedzi na zadawane pytania. Po zakończeniu fazy uczenia nienadzorowanego, następuje faza dostrajania modelu (fine-tuning process) na mniejszym zbiorze danych specyficznym dla określonego zadania. Ten proces pozwala modelowi dostosować swoje umiejętności i swoją wiedzę do określonych zadań, czyniąc go bardziej skutecznym.
Następnie model przechodzi do fazy głębokiego uczenia się (deep learning), wykorzystuje do tego architekturę transformera. To pozwala modelowi zrozumieć zależności między słowami i pojęciami, uczy rozpoznawania ich przy pomocy mechanizmu samouwagi. Po zakończeniu tych wszystkich faz model jest gotowy do praktycznego wykorzystania.
Potężne narzędzie przyszłości?
Custom LLM – Przyszłość Przetwarzania Języka Naturalnego
Custom LLM to technologia, która umożliwia tworzenie i trening własnych modeli językowych o dużych rozmiarach, które są zdolne do automatycznego rozumienia (natural language understanding), generowania ludzkiego języka (natural language generation) i interakcji z nim. Główną techniką używaną do trenowania tych modeli jest uczenie maszynowe, które również wykorzystuje ogromne zbiory danych tekstowych, aby nauczyć model rozumienia semantyki oraz struktury języka.
W ciągu ostatnich lat NLP (natural language processing – przetwarzanie języka naturalnego) przeszło prawdziwą rewolucję dzięki wprowadzeniu niestandardowych dużych modeli językowych. Modele te, znane jako Custom Large Language Models, stanowią niejako przełom w dziedzinie sztucznej inteligencji, umożliwiając dostosowywanie i wykorzystywanie ogromnej ilości danych tekstowych w sposób innowacyjny.
Niestandardowe duże modele języka to rozwinięcie ogólnych modeli języka, takich jak GPT-3 (Generative Pre-trained Transformer 3) czy BERT (Bidirectional Encoder Representations from Transformers), które są znane na całym świecie.
Custom LLMs idą jednak dalej niż modele ogólne, pozwalają bowiem użytkownikom dostosowywać je do konkretnych potrzeb. Oznacza to, że można je trenować na wyspecjalizowanych danych, aby lepiej radziły sobie z określonymi dziedzinami, generowały treści o określonym stylu lub wykonywały konkretne zadania w przetwarzaniu języka naturalnego.
Istnieją różne aspekty, które można dostosować w Custom Large Language Models, takie jak:
- Fine-tuning: Można dostosować takie modele, przekształcając je na potrzeby określonego zadania. Na przykład można wytrenować ogólny model, aby działał lepiej w konkretnej dziedzinie, takiej jak medycyna, prawo lub finanse.
- Dodawanie wyspecjalizowanych danych: Dostosowywanie polega także na dostarczeniu modelowi specjalistycznych danych dotyczących konkretnej dziedziny w celu zwiększenia jego wiedzy w tej dziedzinie (dodając dane zawierające specjalistyczną terminologię (industry specific terminology).
- Ograniczenia treści: Można dostosować modele do wydawania bardziej konkretnej lub bezpiecznej treści, eliminując generowanie treści niestosownej lub niebezpiecznej.
- Różne języki: Custom Large Language Models można dostosowywać do obsługi wielu języków lub dialektów.
- Kontrola stylu generowanego tekstu: Dostosowywanie może obejmować kontrolę nad stylem generowanego tekstu, na przykład, aby zapewnić, że tekst będzie bardziej formalny lub bardziej nieformalny, zależnie od potrzeb.
Te modele znalazły zastosowanie w różnych dziedzinach, takich jak generowanie treści, tłumaczenie automatyczne, analiza sentymentu, chatboty i wiele innych. Dzięki swojej elastyczności CLLM mogą być dostosowane do wielu zastosowań i stanowią istotne narzędzie w dziedzinie przetwarzania języka naturalnego.
Gdzie można zastosować LLM?
Przykłady wykorzystywania LLM są różnorodne, począwszy od generowania treści, analizy danych, sporządzania dokumentów, tworzenia kodów informatycznych, czy też do tłumaczenia na języki obce.
Możliwości wykorzystania LLM są niemal nieograniczone.
- LMM może służyć do generowania treści, artykułów, tworzenia sloganów, haseł w różnych językach itp. Firmy i twórcy treści wykorzystują niestandardowe modele do tworzenia treści na swoich stronach internetowych, blogach, mediach społecznościowych i innych platformach. Modele są używane także jako narzędzie wspomagające procesy twórcze i projektowe. Marketingowcy stosują je na dużą skalę do generowania pomysłów, uzupełniania treści lub obmyślania strategii marketingowych.
- Może pełnić rolę wyszukiwarki internetowej – odpowiada na zadane przez użytkownika pytania.
- LLM może również służyć w tłumaczeniu maszynowym, modele można dostosować do tłumaczenia tekstu z jednego języka na inny, co ułatwia komunikację między kulturami i narodami.
- Wirtualny asystent, chatbot to kolejne funkcje, jakie może przejąć model językowy. Chatboty oparte na niestandardowych modelach są bardziej elastyczne i mogą obsługiwać klientów na stronach internetowych, dostarczając szybkie i trafne odpowiedzi.
- Chat GPT jest w stanie pisać nawet kody informatyczne, może być wykorzystywany do programowania. Korzystając z danych, które zostały przetworzone w przeszłości, model jest w stanie stworzyć np. program komputerowy.
- Modele te mogą być wykorzystywane w edukacji, pomagając w tworzeniu zasobów edukacyjnych, generowaniu pytań i odpowiedzi na quizy oraz w nauczaniu języków obcych.
- Custom Large Language Models pomagają firmom monitorować opinię publiczną na temat ich produktów i usług, analizując miliony recenzji i komentarzy. W biznesie te modele mogą służyć jako narzędzia do tworzenia spersonalizowanych rekomendacji dla klientów, generowania tekstu w różnych dziedzinach, takich jak dziennikarstwo lub reklama, bądź też do analizy danych.
Zalety i wady LLM
Modele mogą przynieść wiele korzyści dla firm i pojedynczych użytkowników. Mogą być dostosowane do konkretnych potrzeb, a dodatkowe szkolenie pozwala tworzyć modele idealnie dopasowane do różnych zastosowań, opracowanych specjalnie pod danego użytkownika lub dane przedsiębiorstwo czy branżę. Jeden LLM może być używany w wielu różnych przypadkach, co czyni go elastycznym i uniwersalnym.
Nowe modele językowe są szybkie i wydajne, a te, które są wytrenowane na dużej ilości danych, są też dokładne i precyzyjne.
Duże modele językowe mają też wady i ograniczenia, o których także należy wspomnieć. Wśród największych ograniczeń jest brak pełnego rozumienia kontekstu, modele nie zawsze są w stanie zrozumieć kontekst w taki sposób jak ludzie. Wynika to z tego, że opierają się na statystykach, a nie na rozumowaniu w sposób ludzki.
Modele językowe często generują tzw.„halucynacje, czyli nieprawdziwe, fałszywe wyniki. Nie rozumieją treści, tylko generują odpowiedzi na postawie danych, które zostały dostarczone do trenowania. Odpowiedzi są generowane na podstawie prawdopodobieństwa występowania słów w określonej kolejności. LMM mogą zatem wprowadzać błędy związane z brakującymi informacjami w treningowym zbiorze danych. W uproszczeniu modele te mogą generować jedynie treści podobne do tych, na których zostały wytrenowane, co znaczy, że nie są w stanie wyciągać samodzielnych wniosków ani generować informacji wychodzących poza swój zakres danych.
Kolejną bardzo istotną wadą modeli językowych jest duży koszt ich stworzenia i utrzymania.
Etyka
Mimo że Large Language Models przynoszą wiele korzyści, wiążą się także z wyzwaniami związanymi z etyką i bezpieczeństwem. Istnieje ryzyko nadużywania tych modeli do rozpowszechniania dezinformacji, generowania nieodpowiednich treści lub naruszania prywatności.
Wiele osób widzi w LMM zagrożenie i ze strachem spogląda w przyszłość, zastanawiając się, kiedy sztuczna inteligencja przejmie miejsca pracy człowieka. Nie traktujmy LLM jako zagrożenia dla naszych miejsc pracy, raczej traktujmy je jako pomoc, wsparcie pracy człowieka. LLM raczej zmieniają sposób, w jaki człowiek wykonuje swoją pracę.
Podsumowanie
Szybki rozwój sztucznej inteligencji (AI) sprzyja powstawaniu nowych modeli językowych oraz udoskonalaniu już istniejących.
Duże modele językowe mają zarówno wady, jak i zalety. Są w stanie w skuteczny sposób wspomagać działania naukowe, rozwiązywać różnorodne zadania związane z przetwarzaniem języka naturalnego. Wspomagają także działania kreatywne poprzez generowanie rozmaitych treści. Z drugiej strony modele te mają nadal wiele ograniczeń i mimo ciągłego rozwoju ich działanie nie jest bezbłędne. Mają ogromny potencjał i jeżeli użytkownik jest świadomy tych ograniczeń, to jest w stanie wykorzystywać działanie LMM w wielu dziedzinach. Jednak w miarę rozwoju tej technologii ważne jest, aby równocześnie uwzględniać kwestie etyki i bezpieczeństwa, aby zapewnić odpowiednie wykorzystanie Custom Large Language Models.



